
“Prompt Engineering” is a book that clearly communicates its target audience from the very beginning. And that’s a good thing, because this is not a book for a casual chat user who simply wants to “talk better with AI.” It is primarily aimed at developers and prompt engineers who actually build on top of models and need to understand how they work, their limitations, and best practices in order to consistently create better prompts. A regular user will quickly feel overwhelmed—and understandably so, since part of the material requires solid familiarity with LLMs, including at the API level.
Let’s start with the less pleasant aspects: there are some language errors, occasionally distracting. Some sections feel overcomplicated and unnecessarily stretched. There are also surprising phrases, such as “LLM common sense,” which do not entirely fit—although I understand the author’s intention.
However, once you move past these weaker moments, it becomes clear that the authors follow a thoughtful and transparent approach. They discuss various techniques, presenting both their advantages and drawbacks, which helps the reader understand exactly where specific recommendations come from. This builds real awareness and competence—not just “apply this rule,” but why you are applying it.
A major strength lies in the visual examples—many discussed concepts are supported by graphical representations. And it works: ideas that initially sound abstract suddenly become intuitive. Additionally, there are exercises that force you to think and help structure your knowledge.
I also appreciate the authors’ approach: before building prompts, you first need to understand how an LLM works. Why it behaves the way it does. Where incorrect answers come from. How tokenization connects to prompt precision. It may sound academic, but in practice it significantly improves later prompt work. The long introduction may feel overwhelming at first—but I know that pain, as I encounter the same reaction in my own training sessions.
Some elements are genuinely fresh—for example, dynamic construction of system prompts. Honestly, I have not seen this framed in quite this way in other publications.
A big plus for the research references, which allow readers to verify sources and dive deeper into specific topics.
Unfortunately, parts of the book are already outdated. There is a strong focus on GPT-3, so some details are no longer current. You will find recommendations that no longer make sense today (e.g., regarding “echo”). On the other hand, this also highlights which concepts have proven timeless. For instance, while the description of tool calling does not mention MCP, it explains the underlying protocol mechanics quite accurately. So even though the book refers to older technologies, it does not lose its practical relevance.
One final observation: many introduced terms initially sound unfamiliar, but this is largely due to the Polish translation. The English equivalents feel much more natural.
Summary
It is an uneven book—sometimes overly detailed and stretched—but at the same time full of concrete, practical, and well-explained guidance. If you build prompts professionally, it will give you solid foundations. If you use LLMs occasionally, this is not the book for you. For engineers, however—it is worth it.





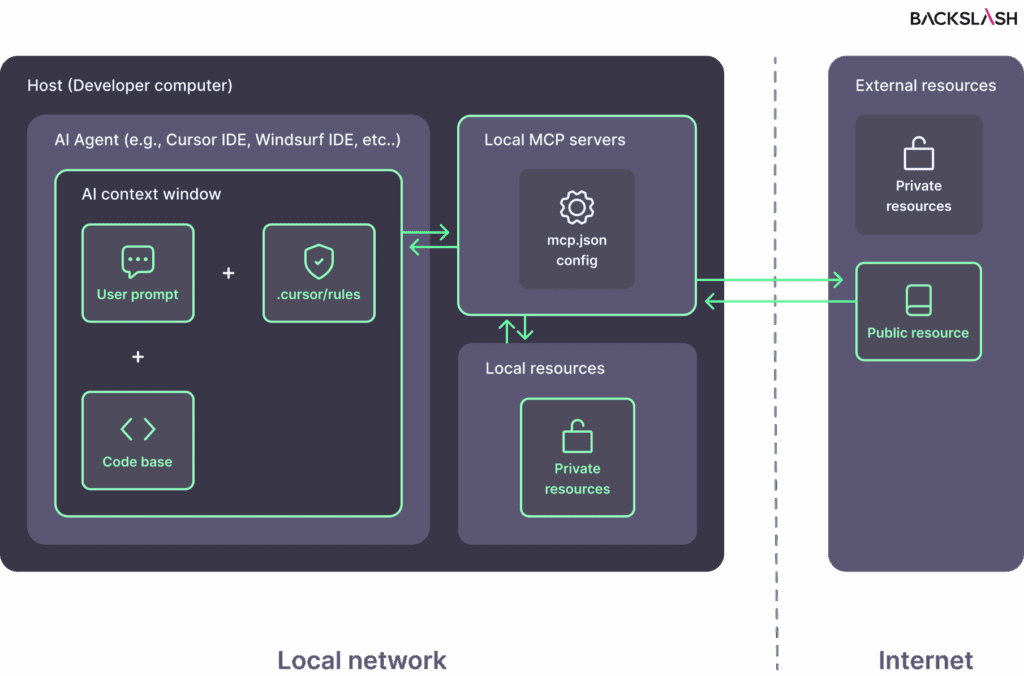
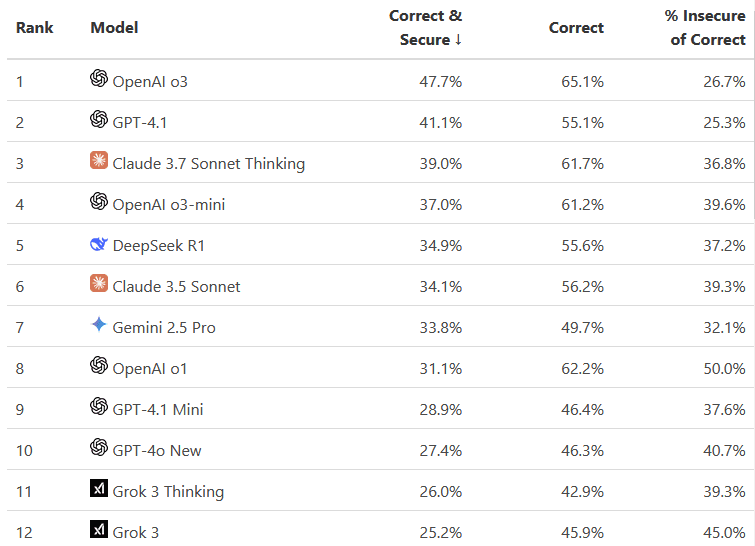

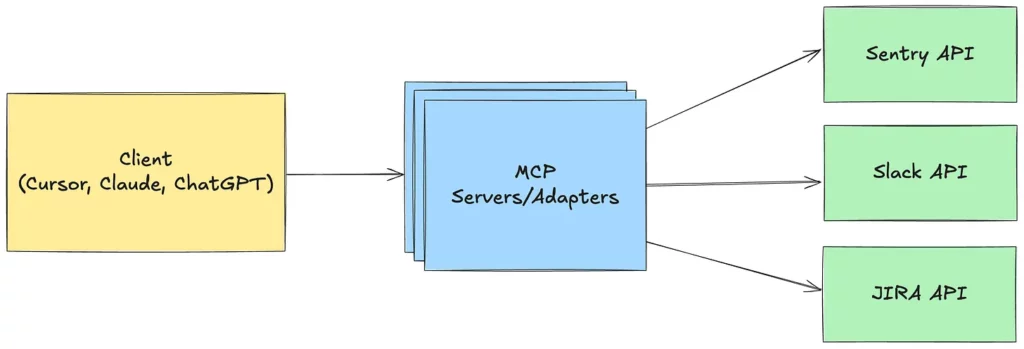

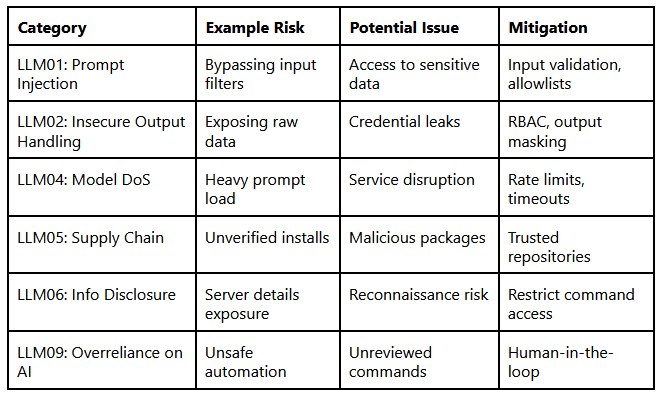
{kind=link}