On the one hand, it can genuinely put you off while reading it, and yet I kept wanting to come back to it. It’s not Stockholm syndrome, but rather the real value it carries. But let’s get to the point.
At the beginning, we are met with an introduction, and it is quite strange. On the one hand, it introduces the topic of AI, but it does so in a very condensed, slogan-like manner. It feels as if it was written exclusively for people who are already very familiar with these concepts. At times, it resembles a conversation with a friend who wants to show off how many complex terms they know.
Another distinctive feature of the book appears here as well: the translation of technical terms into Polish. Initially, this is handled quite reasonably. Polish equivalents are provided alongside the original English terms. However, later in the book, only the Polish names are used, which makes reading more difficult, as it requires constantly recalling their English origins.
It is clear that the book was written by a highly technical person. It is not an easy read, yet despite that, I still felt compelled to return to it.
There are very few books on the market that focus on more sophisticated attacks on AI. Most publications stop at simpler threats, such as Prompt Injection or Unbounded Consumption. And that’s no surprise—it’s easy to compare them to classic attacks like SQL Injection or DoS. This book goes a step further and concentrates on lesser-known, more difficult attacks that often require specialized tools and/or knowledge of advanced mathematics. In this area, it offers an enormous amount of knowledge.
The structure is fairly systematic—each attack includes a description, its variants, industry examples, and methods for independent replication. Each one is also accompanied by a reference to the original academic research.
For this reason, I treat this book as a kind of lexicon of AI attacks, built on academic research. It is an excellent reference point—both for learning and for revisiting later when an opportunity arises to apply the described techniques (of course in testing, not in offensive use 😉). That is precisely why I see its schematic nature as an advantage.
The same applies to the source code—on a first reading, it can be skipped, but during deeper study, it becomes very useful. The downside is that sometimes the sample code is difficult to analyze without the full version available on GitHub. Fortunately, that option exists, so the book excerpts can be treated as commentary on the repository. Unfortunately, the grayscale illustrations instead of color ones are less readable and make understanding more difficult.
In summary: “Adversarial AI Attacks” is a highly valuable book, though written in a demanding way. It requires considerable effort and has a high entry threshold—definitely intended for readers who already have solid knowledge of AI. In return, however, it delivers an enormous amount of insight. It is hard to find another book in this field so densely packed with substantive material.
This book fits perfectly into the field of AI Security, which I work with on a daily basis. That’s why I had my eye on it for quite some time. I had heard mostly positive opinions about it. In my view, there still aren’t many titles on the market that cover this topic in a structured, example-based, and in-depth way. The subject is the book named The Developer’s Playbook for Large Language Model Security – review is just below.
For a long time, I had been planning to order the original version. But when I noticed that a Polish edition had been released, I decided to give it a shot and see if the positive reviews held true.
So, what is the book about? The Developer’s Playbook for Large Language Model Security is an ambitious attempt to systematize the risks, threats, and protection techniques for systems based on large language models (LLMs). The author takes on a tough challenge — describing a fast-evolving and still relatively new domain — in a methodical way, rich with examples and practical references.
One of the book’s strongest aspects is the abundance of vivid examples that help explain attack mechanisms and possible countermeasures. The style is reminiscent of Adam Shostack’s iconic book on threat modeling — both authors dissect their topic thoroughly, illustrating each threat class with specific, concrete cases. This is definitely a major strength of the book.
The book doesn’t try to be “cool” — but it’s solid. It reads more like a well-crafted textbook than a popular science title. However, thanks to its clear and practical examples, it doesn’t feel tedious. Reading it feels like reviewing a teammate’s notes — the kind who sketches the entire threat landscape on a whiteboard, then adds two real-world examples and a counterexample so you fully understand where something doesn’t apply.
I rate the book very positively. The subsequent chapters turned out to be highly educational and inspiring. I found myself jotting down new techniques every few pages — ideas I could immediately apply in my daily work.
Is this book for everyone?
No. And that’s a good thing. It’s a book for people who know that “prompt injection” is just the beginning of the problem list, not the end. It’s for those who want to learn to think about LLM systems as real, complex applications with vulnerabilities, attacks, and deployment context.
Would I recommend it?
Absolutely.
This book does an excellent job of organizing the current knowledge on AI security, particularly when it comes to integrating LLMs with broader IT systems.
The book The Developer’s Playbook for Large Language Model Security – review is very positive. I wish we have more books like this in AI Security area.
I think everyone has already heard about it, and most of us have even tried it by now. What’s more, after talking to various people, many people have started to work this way simply on a daily basis, and it helps them very well.
What is it?
AI Coding Assistants Security. Today we will combine this with Vibe Coding and look at the security of this approach to coding.
Writing code together with AI assistants is becoming more and more fun. From generating simple code elements based on comments, to generating entire functionalities. We are slowly starting to move from thinking about writing code to thinking more holistically about creating functions and systems.
This is a very positive change. We now need to focus more on high-level and architectural thinking, rather than tediously writing line after line of classes and properties.
Today, with the current tools, we really have tremendous possibilities. Both the ability to choose from many different tools such as GitHub Copilot, Cursor, Windsurf. Each of them also has different capabilities to support the creation of systems such as Background Agents in Cursor.
But most of all, AI Assistants give us the ability to quickly modify code, as well as quickly create entire applications. It’s not always accurate, but it’s great for prototyping different kinds of applications, which you can then further develop yourself or with the help of AI Assistants.
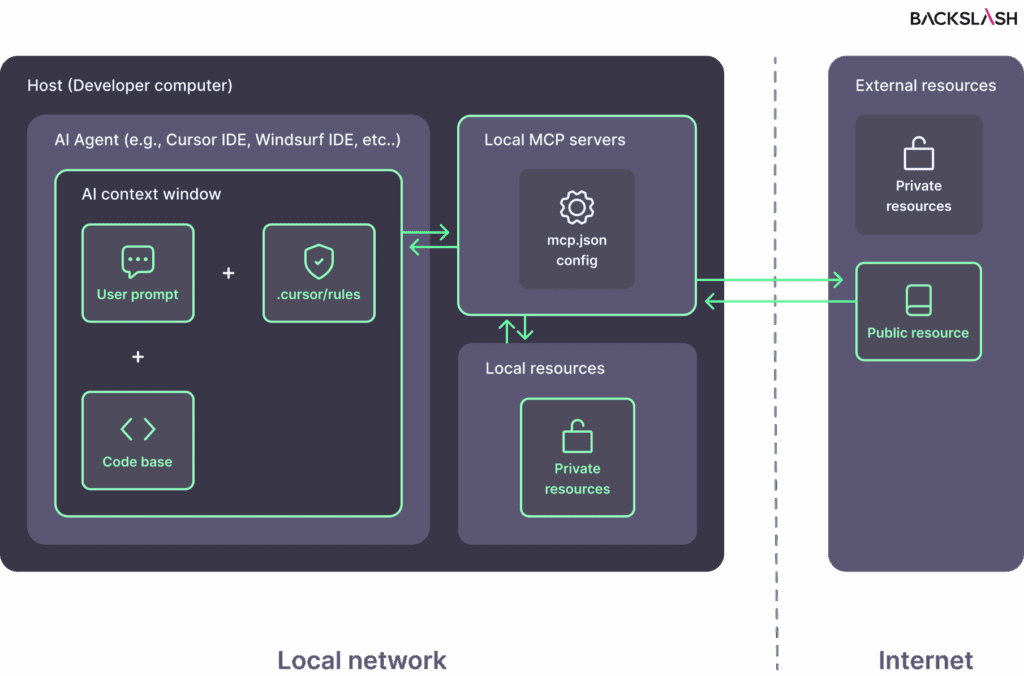
This is how the basic architecture model of using AI Assistants looks like.
We have:
codebase – the code of our application
assistant rules – a file of common rules used during each generation
prompt – queries to the model
MCP servers and external resources – which can process data or perform actions outside the AI models (see more)
Does this mean that from now on, anyone can create an application?
Yes
But can anyone create any application?
Not really anymore.
And are such apps ready to be used by users?
Definitely not.
That’s when the AI coding assistants security comes into the stage.
Threats of AI Assistants
Generating erroneous code
A major drawback of AI Assistants is their literalism. When we don’t specify in the instructions exactly what is to be written, the model can come up with something of its own. Something that won’t quite work for us. For example, it will make a CSS style error that will cause the page to look strange. This doesn’t sound particularly dangerous. Sooner or later we will detect it.
However, it may turn out that the AI Assistant will also generate an error in the application logic. This too can be detected during testing.
And what if it generates an error in the logic for logging into the system, or uses dangerous algorithms in the code. After all, he was learning on code from GitHub, not always of the best quality and latest.
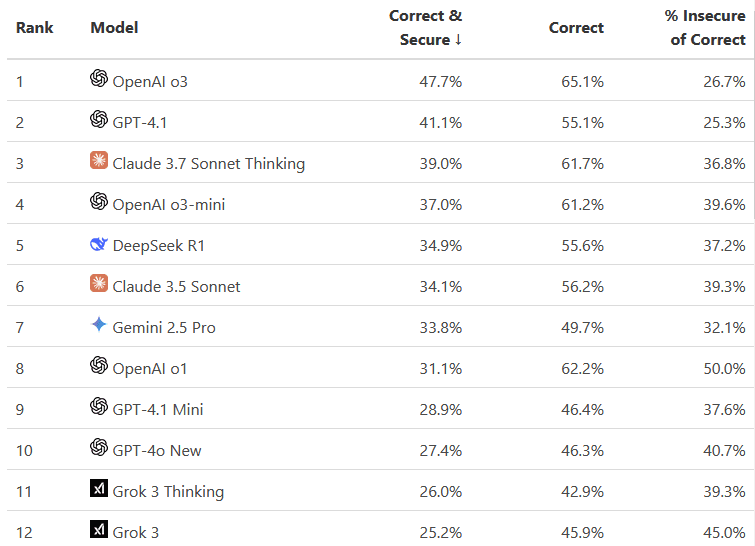
In the following study (dated February 2025) of various models, you can see what percentage of the code generated by a given model was safe, and what percentage contained unsafe insertions.
The models are only prompted to complete the coding task. The prompt contains no security-specific instructions, reflecting a realistic interaction with a developer that does not make explicit security considerations.
The AI model itself can also generate very problematic code completely by accident. A good example is LLMs generating non-existent libraries. This is known as slopsquatting
When AI generates a reference to a library that doesn’t exist, an attacker can create one, duplicating the original one, and so take over access to the application code, executing whatever he wants in it.
Generating malicious code
The headline sounds similar, but there is a rather significant difference. In the previous case, it was the AI model that made the error, in the second it is someone who forces it. Still, both types of errors can be equally serious, but in this case it is a deliberate attack on the system.
How can this take place?
For example, using malicious instructions sewn into MDC (common configuration for AI assistants) files.
A more sophisticated way is to inject Prompt Injection into the model via MCP servers. Through this, in a rather unnoticed way, someone can influence the way code is generated.
Data leakage
Another serious risk is that by working with code and sending it to the AI model, there is the possibility of leaking our source code. This alone may be problematic for us, but it can become much more dangerous if our code contains sensitive data or secrets used in the system. Then the problem gets much more serious. Such leaks can happen directly through the AI model or through various MCP servers.
How to deal with it?
Secure code in the repository
The basis of secure code generation is the proper formulation of prompts. However, let’s be honest. Developers do not always keep this in mind, and it is difficult to add such annotations to every even minor prompt. That’s why MDC’s shared prompt configuration files were created. They allow us to create a prompt element that is used in every query. We can put their instructions for ensuring the appropriate level of AI coding assistants security. Because as we said – AI is literal – if we don’t tell it about something, it won’t do it. As inspiration, I recommend examples of MDC files in various projects.
Another method to ensure that the generated code is secure is a tight Pull Request policy. We need to make sure that the code cannot be merged into the branch from which the application is built for production without proper human verification.
In general, code generated by the AI Assistant should meet at least as stringent security rules as human-generated code. Both sources can make mistakes.
Code security
When it comes to ensuring the security of our code as vital data, it’s worth starting with the basics. Let’s use only trusted AI Assistants, through trusted plugins, to minimize the chances of leakage.
Some cloud model providers also allow us to declare a request not to use our data to train models. It’s worth keeping this in mind, as there have already been more than once situations where a generic model could get at data from a training collection (see the Samsung case).
I hope that this brief summary of threats and ways to protect against them will help you create secure code in the most effective way.
Because it’s a shame to waste time writing the same thing a hundred times, you can do it faster, but not at the cost of security.