I think everyone has already heard about it, and most of us have even tried it by now. What’s more, after talking to various people, many people have started to work this way simply on a daily basis, and it helps them very well.
What is it?
AI Coding Assistants Security. Today we will combine this with Vibe Coding and look at the security of this approach to coding.
Writing code together with AI assistants is becoming more and more fun. From generating simple code elements based on comments, to generating entire functionalities. We are slowly starting to move from thinking about writing code to thinking more holistically about creating functions and systems.
This is a very positive change. We now need to focus more on high-level and architectural thinking, rather than tediously writing line after line of classes and properties.
Today, with the current tools, we really have tremendous possibilities. Both the ability to choose from many different tools such as GitHub Copilot, Cursor, Windsurf. Each of them also has different capabilities to support the creation of systems such as Background Agents in Cursor.
But most of all, AI Assistants give us the ability to quickly modify code, as well as quickly create entire applications. It’s not always accurate, but it’s great for prototyping different kinds of applications, which you can then further develop yourself or with the help of AI Assistants.
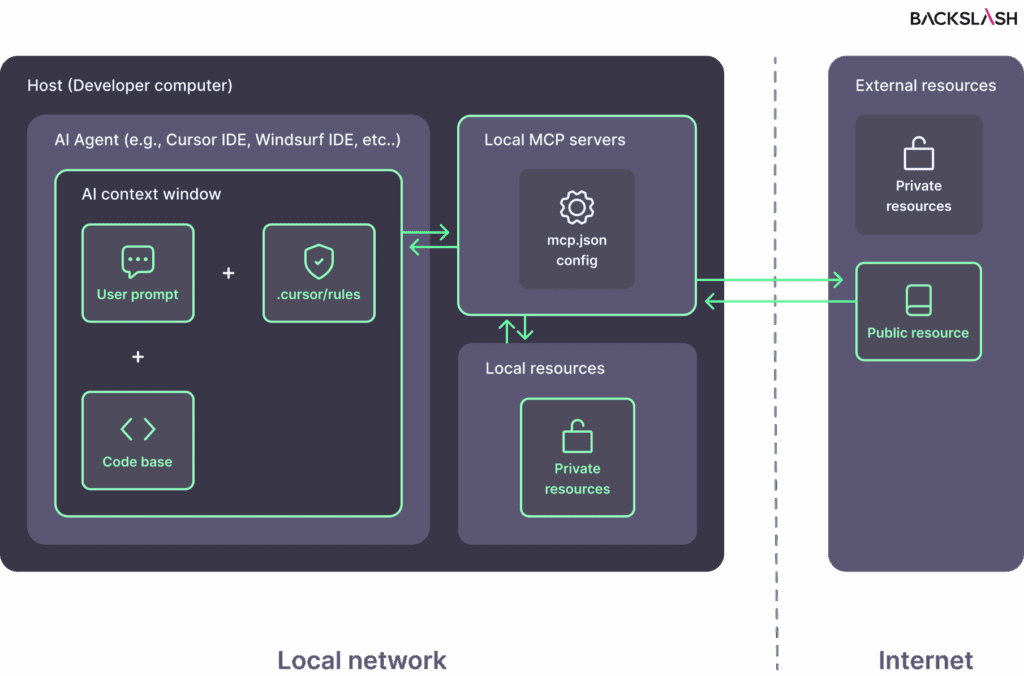
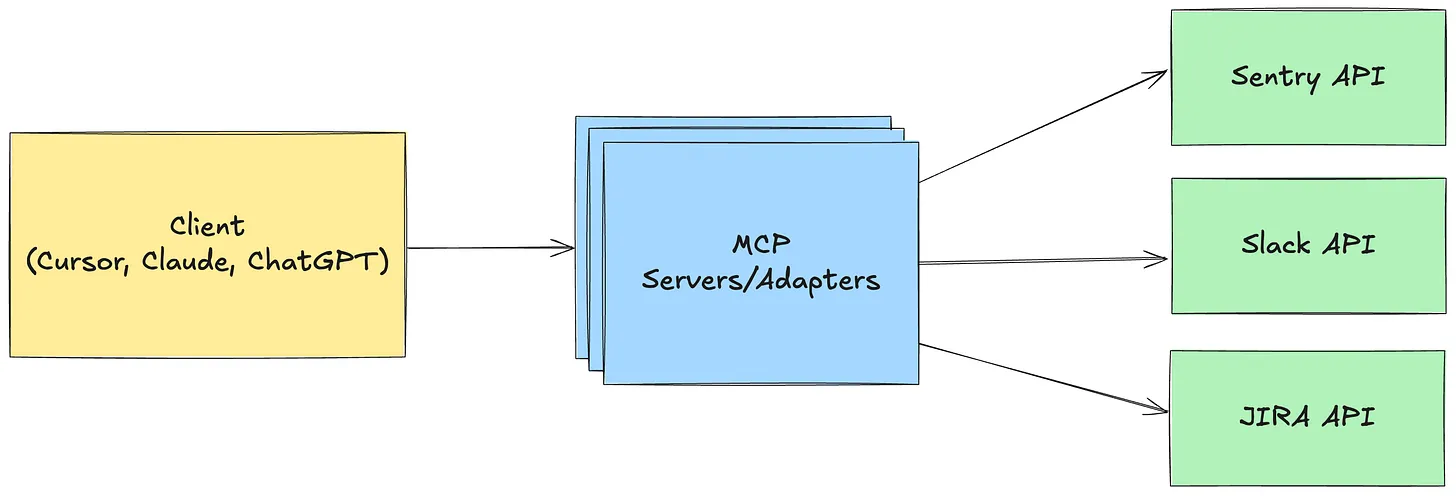
This is how the basic architecture model of using AI Assistants looks like.
We have:
codebase – the code of our application
assistant rules – a file of common rules used during each generation
prompt – queries to the model
MCP servers and external resources – which can process data or perform actions outside the AI models (see more)
Does this mean that from now on, anyone can create an application?
Yes
But can anyone create any application?
Not really anymore.
And are such apps ready to be used by users?
Definitely not.
That’s when the AI coding assistants security comes into the stage.
Threats of AI Assistants
Generating erroneous code
A major drawback of AI Assistants is their literalism. When we don’t specify in the instructions exactly what is to be written, the model can come up with something of its own. Something that won’t quite work for us. For example, it will make a CSS style error that will cause the page to look strange. This doesn’t sound particularly dangerous. Sooner or later we will detect it.
However, it may turn out that the AI Assistant will also generate an error in the application logic. This too can be detected during testing.
And what if it generates an error in the logic for logging into the system, or uses dangerous algorithms in the code. After all, he was learning on code from GitHub, not always of the best quality and latest.
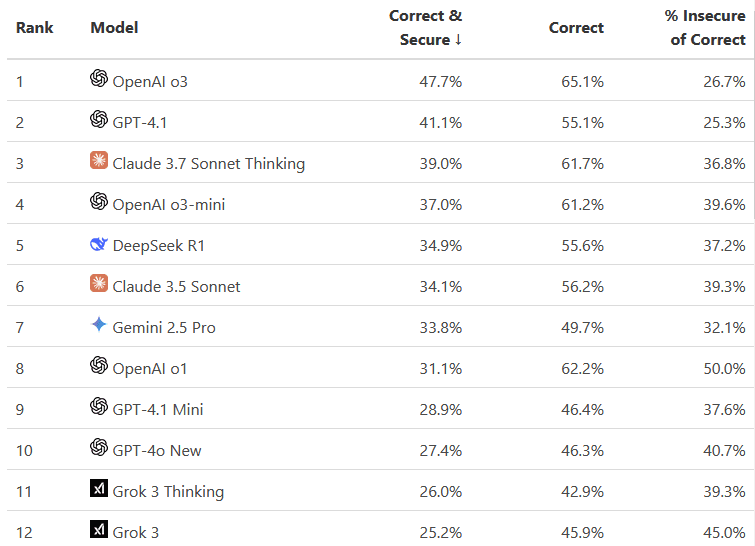
In the following study (dated February 2025) of various models, you can see what percentage of the code generated by a given model was safe, and what percentage contained unsafe insertions.
The models are only prompted to complete the coding task. The prompt contains no security-specific instructions, reflecting a realistic interaction with a developer that does not make explicit security considerations.
The AI model itself can also generate very problematic code completely by accident. A good example is LLMs generating non-existent libraries. This is known as slopsquatting
When AI generates a reference to a library that doesn’t exist, an attacker can create one, duplicating the original one, and so take over access to the application code, executing whatever he wants in it.
Generating malicious code
The headline sounds similar, but there is a rather significant difference. In the previous case, it was the AI model that made the error, in the second it is someone who forces it. Still, both types of errors can be equally serious, but in this case it is a deliberate attack on the system.
How can this take place?
For example, using malicious instructions sewn into MDC (common configuration for AI assistants) files.
A more sophisticated way is to inject Prompt Injection into the model via MCP servers. Through this, in a rather unnoticed way, someone can influence the way code is generated.
Data leakage
Another serious risk is that by working with code and sending it to the AI model, there is the possibility of leaking our source code. This alone may be problematic for us, but it can become much more dangerous if our code contains sensitive data or secrets used in the system. Then the problem gets much more serious. Such leaks can happen directly through the AI model or through various MCP servers.
How to deal with it?
Secure code in the repository
The basis of secure code generation is the proper formulation of prompts. However, let’s be honest. Developers do not always keep this in mind, and it is difficult to add such annotations to every even minor prompt. That’s why MDC’s shared prompt configuration files were created. They allow us to create a prompt element that is used in every query. We can put their instructions for ensuring the appropriate level of AI coding assistants security. Because as we said – AI is literal – if we don’t tell it about something, it won’t do it. As inspiration, I recommend examples of MDC files in various projects.
Another method to ensure that the generated code is secure is a tight Pull Request policy. We need to make sure that the code cannot be merged into the branch from which the application is built for production without proper human verification.
In general, code generated by the AI Assistant should meet at least as stringent security rules as human-generated code. Both sources can make mistakes.
Code security
When it comes to ensuring the security of our code as vital data, it’s worth starting with the basics. Let’s use only trusted AI Assistants, through trusted plugins, to minimize the chances of leakage.
Some cloud model providers also allow us to declare a request not to use our data to train models. It’s worth keeping this in mind, as there have already been more than once situations where a generic model could get at data from a training collection (see the Samsung case).
I hope that this brief summary of threats and ways to protect against them will help you create secure code in the most effective way.
Because it’s a shame to waste time writing the same thing a hundred times, you can do it faster, but not at the cost of security.
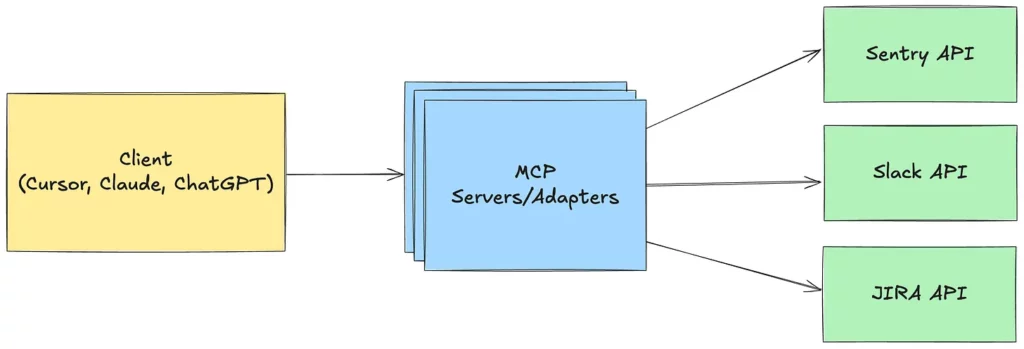
MCP (Model Context Protocol) is the recently announced standardized way for AI models to communicate with the outside world, announced by Claude. Specifically, in the context of accessing data from the outside world.
The above architecture shows that it’s an interface that is able to connect various kinds of APIs using a language that is familiar to AI models. It seems to be just a minor standardization, but it has triggered a creation of multiple new servers for more or less popular services. It’s easy enough that none of the big players want to be left behind, and everyone wants to provide an interface for contact between AI and their system.
You can see how popular it is when you look at the number of new implementations of this protocol.
Also, an interesting and more in-depth description of the protocol itself (MCP), as well as the possibilities for its use and potential future expansion:
The big advantage of this new protocol, as well as its rapid adoption, is that it allows AI to use specialized tools to increase its efficiency. A good example of this is reverse engineering. So far, LLMs have had to rely on their own abilities to do this and analyze code purely at the language layer. With interfaces such as GhidraMCP (https://github.com/LaurieWired/GhidraMCP), it can take advantage of mature solutions and process already preprocessed data.
MCP and security
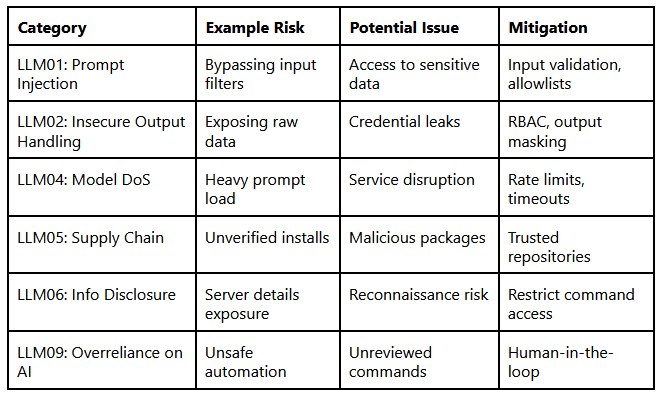
The topic of MCP security can be summarized up in one sentence:
You can also see the vulnerabilities that can exist in the MCP code by seeing the examples.
Intentionally Vulnerable MCP Server (Built to test SQL Injection (SQLi) and Remote Code Execution (RCE) vulnerabilities via FastAPI, JSON-RPC, and LLM-based decision logic.)
An interesting way to verify publicly available MCP servers from different vendors. It is interesting that we can also use this method to verify the security of other libraries or tools
The big problem with MCP servers is the implementation itself. Especially when it is so easy to create such a server. Even more so in the vibe coding model.
The protocol itself does not define any security, which can provoke a poor implementation. However, with the right Zero Trust approach from both sides. As a Client, we don’t know what MCP will return and whether it’s secure, and as an MCP Server, we also have to be distrustful of the input.




{kind=link}